
如何使用 MySQL 的 EXPLAIN 语句进行查询分析?
属性说明
explain主要用来分析SQL查询的执行计划,主要属性如下:
id:查询的执行顺序标识符,值越大优先级越高。如果是单表或没有子查询,id通常为1,;复杂查询(如包含子查询或union),id会有多个。select_type(重要):查询类型,描述查询的复杂程度。
SIMPLE:简单查询,不包含子查询或联合查询(union);PRIMARY:主查询,表示最外层的查询;SUBQUERY:子查询,表示嵌套在主查询中的查询;DERIVED:派生表,表示查询的结果被作为临时表处理;UNION:联合查询中的第二个或后续的select;UNION RESULT:联合查询结果集。
table:查询涉及的表。partitions:查询涉及的分区(仅适用于分区表)。如果表未分区,则为空;如果已经分区,则显示查询实际访问的分区列表。type(重要):访问类型。尽量避免ALL和index类型,优先使用const或eq_ref;从快到慢依次为:
system:表示查询的表只有一行数据(系统表),不常见;const:表示查询的表最多只有一行匹配结果,通常使用主键或唯一索引查询;eq_ref:表示对于每个来自前一张表的行,MySQL仅访问一次这个表。通常发生在使用主键或唯一索引进行连接查询;ref:使用非唯一索引匹配多行数据;range:使用索引范围扫描,通常出现在使用索引的范围查询中(between、>、<、>=、<=);index:全索引扫描,扫描索引中的所有行,而不是表中的所有行。即使索引列的值覆盖查询,也需扫描整个索引;ALL:全表扫描,性能最差。通常出现在没有索引的查询条件中。
possible_keys:可能使用的索引。key(重要):实际用到的索引。key_len:使用的索引长度(字节数)。长度越短,性能越好;可以判断索引是否被完全使用。ref:显示索引哪一列被使用。rows(重要):预估需要扫描的行数,数值越小,性能越好。filtered:显示查询过滤后剩余行占总行数的百分比。值越高,查询条件越有效;rows * filtered / 100 = 最终返回的行数(估算)。Extra(重要):额外信息,关于查询执行的细节:
Using index:使用了覆盖索引Using where:使用了where条件进行过滤Using temporary:使用了临时表储存中间结果Using filesort:使用了文件排序,通常需要优化Using join buffer:使用了连接缓冲区,可能需要优化Impossible WHERE:where条件永远为假,查询无结果Distinct:去重操作
例子
1)先创建一张学生作业表
CREATE TABLE `homework` (
`id` char(20) NOT NULL,
`course` varchar(255) DEFAULT NULL,
`score` int(255) DEFAULT NULL,
`level` varchar(255) DEFAULT NULL,
`teacher` varchar(255) DEFAULT NULL,
`check_time` datetime DEFAULT NULL,
`ho_fk_stu` char(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;2)查询张老师所布置的作业成绩信息,作业id、课程、成绩,并按成绩进行降序:
EXPLAIN SELECT id, course, score FROM `homework` WHERE teacher = '张老师' ORDER BY score DESC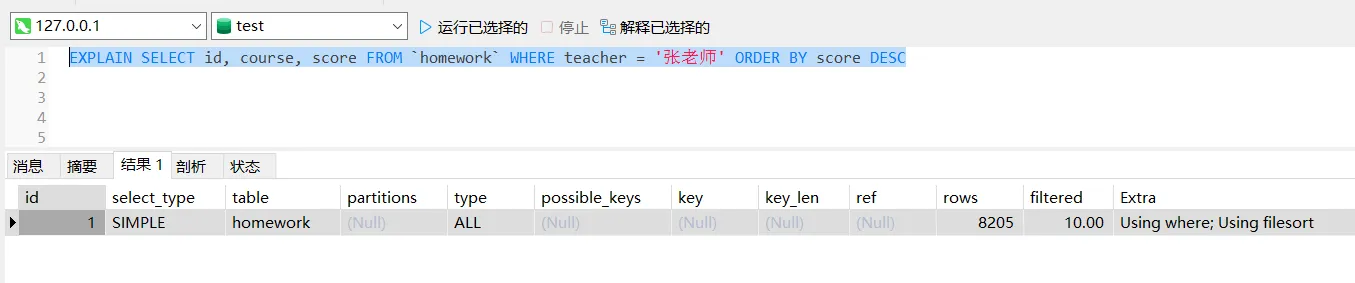
3)简单分析,这是一个简单查询(SIMPLE),全表扫描(ALL),没有使用到索引,扫描了8205行数据,用到了where条件,使用了文件排序
4)找到问题,没有使用索引(条件和排序)
5)优化,创建联合索引
CREATE INDEX idx_teacher_score ON homework(teacher, score);6)分析优化后的结果

type:ref,使用了非唯一索引进行查询;
key:idx_teacher_score,使用该联合索引进行查询;
rows:2,预估扫描行数减少;
Extra:Using where,不再需要文件排序。
索引已经覆盖了条件和排序字段。千万注意满足最左匹配原则。
#MySQL(21)评论